- Published on
Why batch-, time-, and job-based orchestration are false economies
- Authors
- Name
- Marat Levit
- @MaratLevit



Orchestration is hard. Orchestrating the mess that are data platforms is even more challenging. You have countless source systems, all with their delivery schedules, numerous load, transformation, and extraction jobs, each with their dependencies and SLAs. So, as we’ve done for the many years that have passed, we orchestrate all these based on either a batch, a time of day/day of the week, or based on the data pipelines (jobs) themselves.
What we’ve essentially created is a false economy. Will the orchestration work? Sure. Will the orchestration have limitations and be a headache to maintain? Absolutely.
Let’s define the problem
To understand precisely why these methods are inadequate, let’s break them down and point out their deficiencies.
Batch
Batch-based orchestration is simple. You have a logical grouping (batch) of jobs that need to be processed based on either their source system, layer in the data platform or data warehouse. When the batch runs, all the jobs within the batch run. Orchestration occurs between batches. When Batch A completes, Batch B starts and so on.
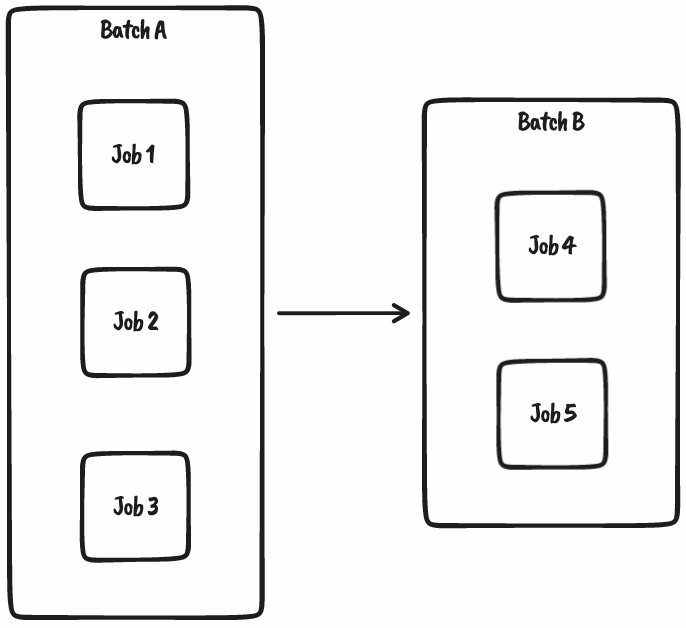
The problem arises when jobs within a batch fail, causing the entire batch to go into a “failed” state. This prevents any downstream batches from running.
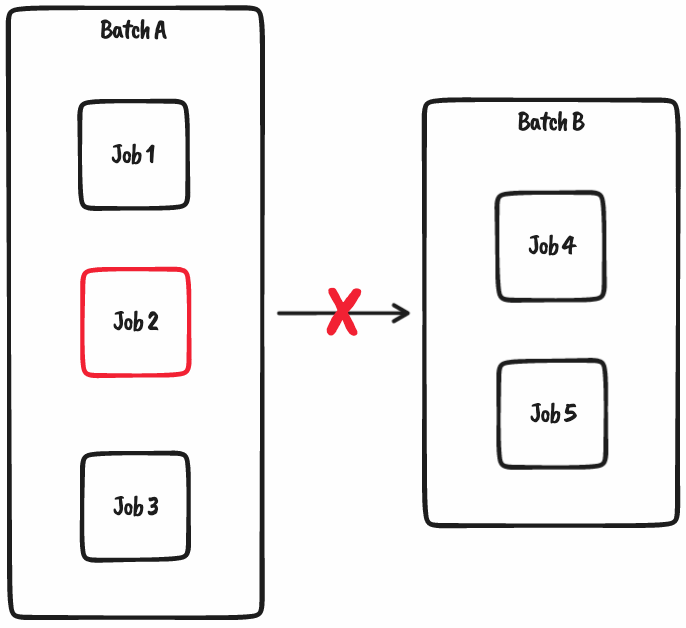
The problem is exacerbated when you consider that (for example) Job 4 and Job 5 in the above diagram weren’t dependant on Job 2 at all. What we’ve done is artificially limit our data platforms performance purely based on a logical grouping of jobs.
Time
Time-based orchestration can, in some instances, be just as bad, if not worse. Time-based orchestration is hard to get right and causes inefficiencies in our compute utilisation.
Let’s discuss this with a simple example. File 1 lands every morning at 8 AM. Job 1 is scheduled to run every morning at 8.05 AM (giving the managed file transfer system enough time to copy the file over).

Now let’s imagine File 1 didn’t arrive until 8.10 AM due to network congestion. Job 1 was executed at 8.05 AM and failed to find File 1. Now, ignoring the fact that another ten downstream jobs will also fail to find their dependant files or tables that are created by Job 1, 2, and so on, we have to build retry mechanisms into Job 1 to try again in 5 minutes, 10 minutes, even an hour.
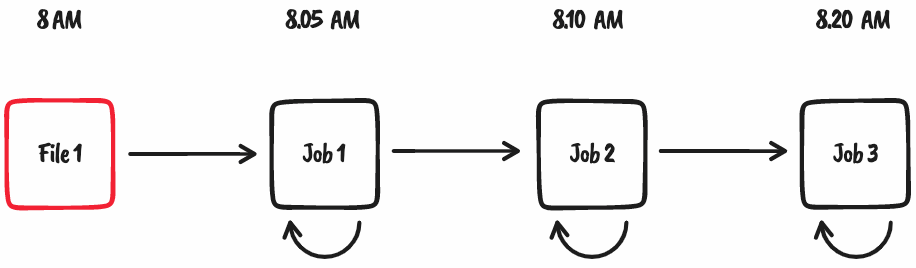
We’re essentially consuming compute cycles to sit around and wait for this to happen at some point in the future.
Job
Job-based orchestration is more granular than batch-based and doesn’t have the same issues as time-based, so it looks like it could be the way forward. Whilst job-based orchestration is better, it still has its problems.
Say we take our batch-based example and delete the batches. What we’re left with are job-based dependencies.
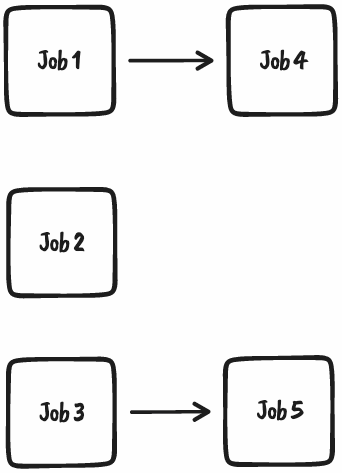
So far, so good. If Job 2 fails as it did in the batch-based example, Job 4 and 5 will not be affected. So we’ve solved one issue.
However, we’ve introduced a second issue—dependency management. In the batch-based world, we only managed dependencies between batches. Say we have five or even ten batches, nothing tough to handle. In a job-based world, we maybe have hundreds of jobs with inter-dependencies that we now need to manage.
Orchestrating and maintaining these dependencies becomes a full-time job for someone, and nobody wants that.
Let’s propose a solution
Now that we’ve identified the problem, what’s the solution? Events and object-based dependencies.
Events
Events are simple. When A happens, do B.
When File 1 lands, run Job 1. No schedules, no wasted compute utilisation sitting around retrying jobs over and over again, hoping File 1 is there this time.

Now, events by themselves are not the answer. They have the same problem as job-based orchestration. Somebody has to maintain all the event dependencies. So, instead of using events on their own, let’s join forces.
Objects
Objects are your files, your tables, your materialised views, your extracts and so on. They are your sources, and they are your targets. Instead of just thinking about our platform at a job level, let’s think about it at the object level.
We’ll take the same example as before, but we’ll introduce the concept of objects and events this time.
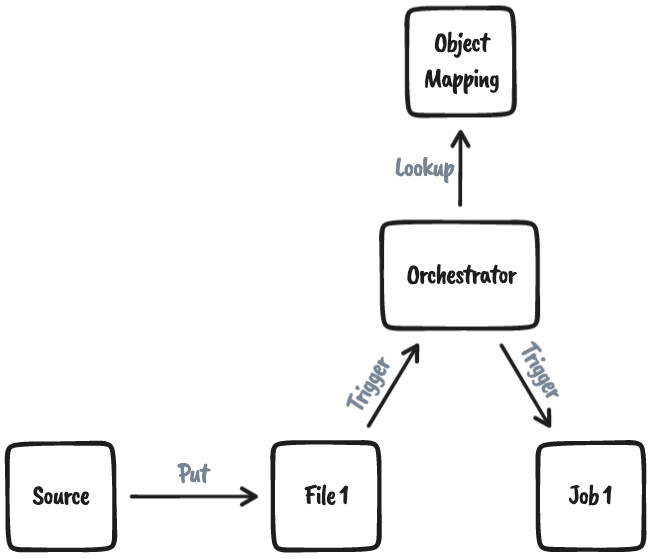
How does this work?
The object mapping is nothing more than a data store (think database, config file etc.) that holds information about each job and the objects that job either depends on from upstream or is the dependant of for downstream.
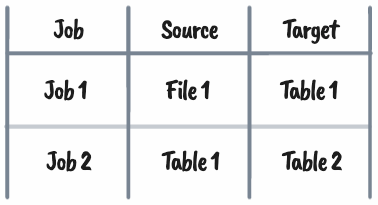
In the above table, we know that Job 1 has File 1 as its source and Table 1 as its target. But more importantly, we know that Job 2 is dependant on Table 1. We, however, don’t need to know which jobs produce Table 1 or when they run or don’t run.
The orchestrator is nothing more than a small app triggered when events occur (i.e., a file lands, a job completes its run etc.). The job of the orchestrator is simple. When a job is run, it performs a lookup against the object mapping data store and computes the next set of jobs that can be run based on the objects the job is dependant on. That’s it.
This works because we, as developers, only need to maintain the object mapping for each job developed.
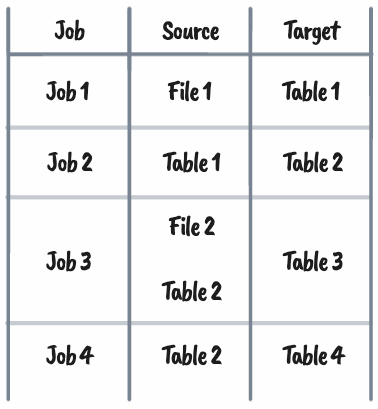
As more jobs are added with dependencies on either existing or new objects (as demonstrated in the table above), the orchestrator handles this for us dynamically at the object level.
We no longer need to worry about which time of day to schedule our jobs to run, which jobs to group into a batch, or have to constantly modify our dependencies within our orchestration tool as new jobs are added, modified, or removed.
Let’s wrap it up
We’ve lived through and suffered with this problem for many years. While specific tools help, think Airflow and dbt, they don’t cover all the bases, and sometimes a custom solution works best.
Let’s put batch-, time-, and job-based orchestration to rest once and for all.
Thanks to Damien C for the chat that inspired this article.